How we improved AI inference on macOS Podman containers
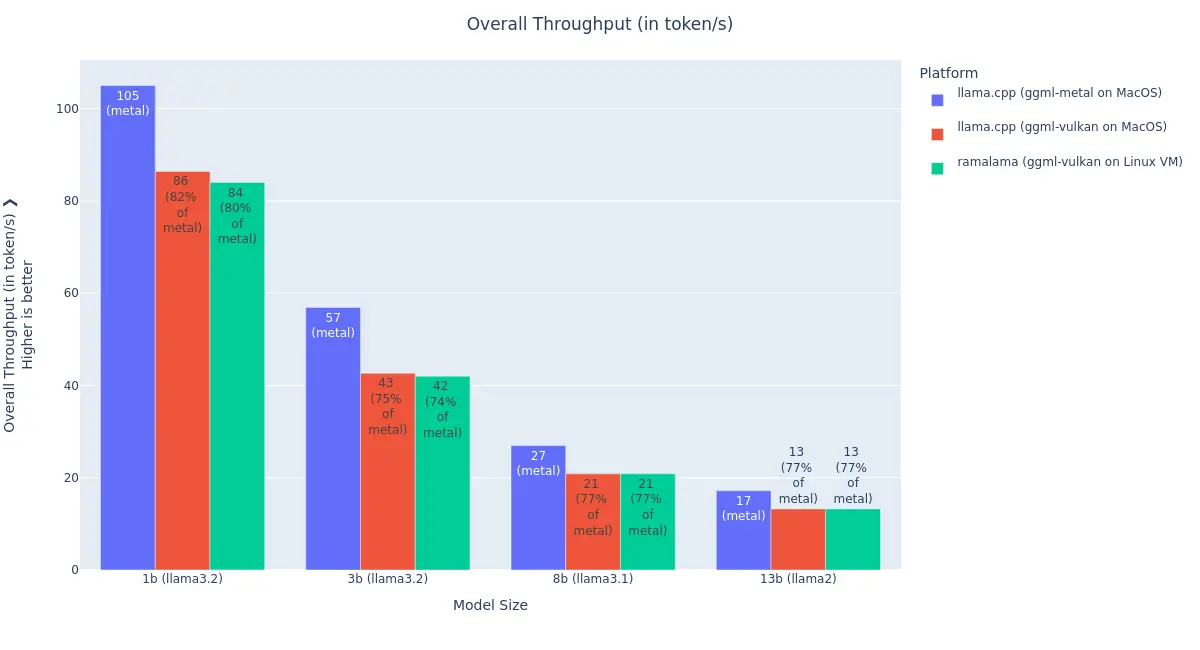
2025-06-05 in RHOAI, CRC, WorkToday we published the results of my MacOS container performance evaluation work, where I reviewed how the recent enhancements of llama.cpp/Vulkan and libkrun improved hashtag#ramalama AI inference performance.
TLDR: 40x, thanks to the enablement and optimization of Vulkan GPU acceleration via para-virtualization, to escape the VM isolation.
Podman MacOS containers, running inside libkrun VMs, now perform at 75-80% of the native speed for AI inference \o/
And that’s not the end of it, as part of my ongoing work, I could get a POC of llama.cpp running at 92% of the native speed! Stay tuned 😊