Reach native speed with MacOS llama.cpp container inference
2025-09-18 in CRC, WorkToday we’ve published my exploratory work to get GPU inference on Podman Desktop/AI Lab and RamaLama up to native speed on MacOS! 🎉🎉🎉
In this platform (like on Windows), containers run inside Linux Virtual Machines. And while the CPU has always been running at full speed, GPU acceleration isn’t so easy.
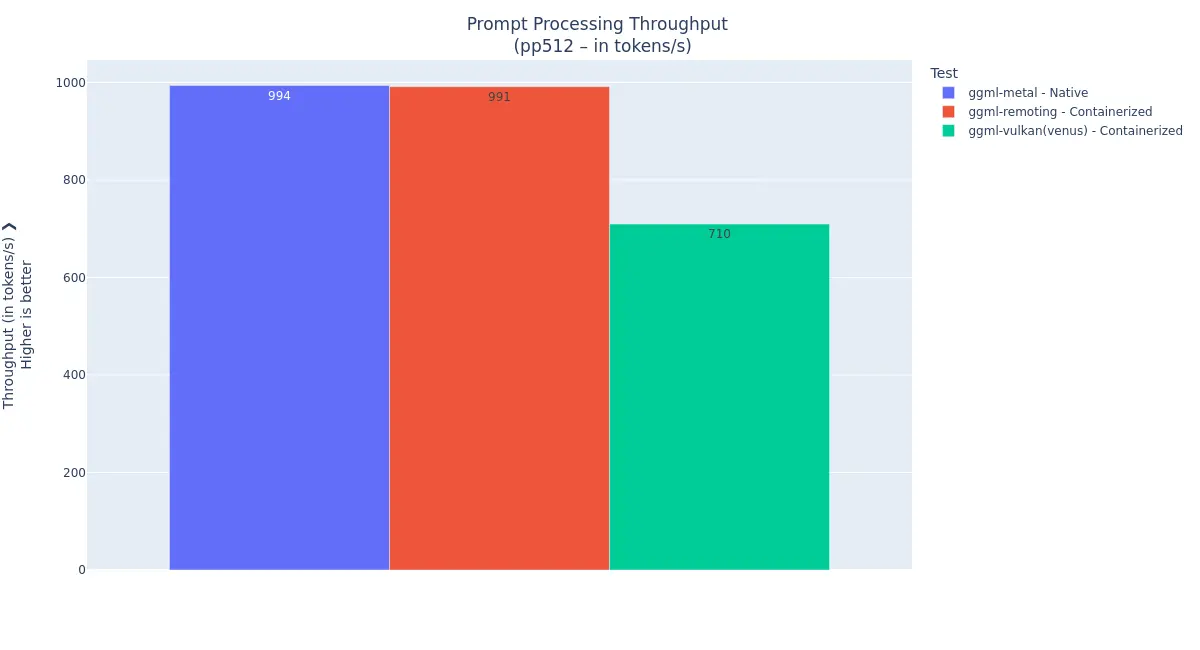
The solution currently available is general-purpose. It enables the Vulkan API to jump out of the VM isolation. But it is limited to 75-80% of the native performance of llama.cpp (see this post https://lnkd.in/eMhm8SnB).
With this POC, we propose to focus on llama.cpp’s GGML interface to cross the VM boundary, and let the ggml-metal backend interact with the GPU. And this choice paid off, as we could demonstrate near-native performance across a range of inference configurations 🎉.
Look at the blog post to see how to test it with Podman Desktop and Ramalama. And of course, everything is open source 😀