Network performance in distributed training: Maximizing GPU utilization on OpenShift
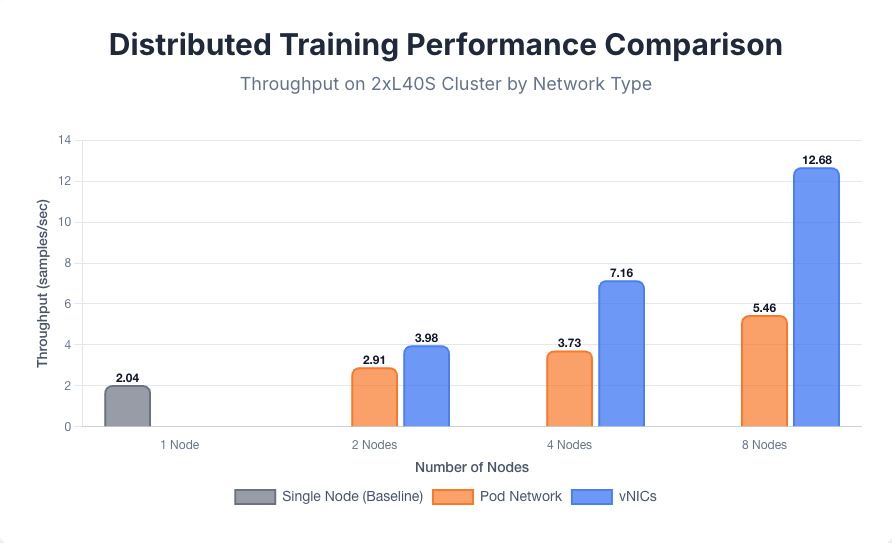
2025-10-16 in RHOAI, PSAP, WorkToday, we published with my teammates Tanya Osokin and Michey Mehta the result of our multi-node distributed training investigation. We benchmarked the scale-up of OpenShift clusters with 8xH100 or 2xL40s GPUs and showed the uttermost importance of the network link inter-connecting the cluster nodes.
With the processing speed of the 8xH100 cluster, a 400 Gbps network was mandatory to improve the training throughput, and for the 2xL40s, a 200 Gbps network was enough.